[TOC]
HTTP发展历史
HTTP(HyperText Transfer Protocol)是万维网(World Wide Web)的基础协议。自 Tim Berners-Lee 博士和他的团队在1989-1991年间创造出的。
HTTP 是基于 TCP/IP 协议的应用层协议。它不涉及数据包(packet)传输,主要规定了客户端和服务器之间的通信格式,默认使用80端口。
- HTTP协议始于1989年蒂姆·伯纳斯-李的一篇论文
- HTTP/0.9是个简单的文本协议,只能获取文本资源(get获取纯文本)
- HTTP/1.0确立了现在使用的大部分技术,但不是正式标准
- HTTP/1.1是目前互联网使用最为广泛的协议,功能也非常完善(第一个标准文档).
- HTTP/2基于Google的SPDY协议,注重性能改善,但还未普及
HTTP1.0:
- 无状态、无连接
HTTP1.1:
- 持久连接
- 请求管道化
- 增加缓存处理(新的字段如
cache-control) - 增加
Host字段、支持断点传输等
HTTP2.0:
- 二进制分帧
- 多路复用(或连接共享)
- 头部压缩
- 服务器推送
1. HTTP/0.9 - 单行协议
HTTP 的最早版本诞生在 1991 年,最初版本的HTTP协议并没有版本号,后来它的版本号被定位在 0.9 以区分后来的版本。
0.9版本及其简单,只有一个GET命令。请求由单行指令构成,其后跟目标资源的路径:
GET /index.html
上面命令表示,TCP 连接(connection)建立后,客户端向服务器请求(request)网页index.html。
协议规定,服务器只能回应HTML格式的字符串,不能回应别的格式:
<html>
<body>Hello World</body>
</html>
服务器发送完毕,就关闭TCP连接。
HTTP 0.9版本缺点:
1、响应内容不包含HTTP头,只能传送HTML文件,无法传输其他类型的文件。
2、没有状态码或错误代码,一旦出错,只能把错误信息放在HTML文件中传回,供人们查看。
2. HTTP/1.0 - 构建可扩展性
1996年,HTTP 1.0版本发布,对0.9版本进行了扩展:
- 在请求方法的后面添加了协议版本号:
GET /index.html HTTP/1.0 - 新增
POST和HEAD命令 - 增加了缓存字段:Expires强缓存, Last-Modified & If-Modified-Since协商缓存
- 增加了HTTP状态码,在响应开始时发送,便于浏览器了解请求执行成功或失败,并响应调整行为(更新或使用本地缓存)
- 引入了HTTP头的概念,无论是对于请求还是响应,允许传输元数据,使协议变得非常灵活,更具扩展新
- 在新HTTP头的帮助下,任何格式的内容都可以发送。这使得互联网不仅可以传输文字,还能传输图像、视频、二进制文件。这为互联网的大发展奠定了基础(
Content-Type) - 多字符集支持、多部分发送(multi-part type)、权限(authorization)、缓存(cache)、内容编码(content encoding)等
HTTP/1.0缺点:
每个TCP连接只能发送一个请求,数据发送完毕连接就关闭,如果还要请求其他资源就必须再新建一个连接。TCP连接成本很高,因为需要客户端和服务器三次握手。所以HTTP 1.0版本性能较差。随着网页加载的外部资源越来越多,这个问题就愈发突出。为解决这个问题,有的浏览器在请求时,会加一个非标准的Connection字段:
Connection: keep-alive
这个字段要求服务器不要关闭TCP连接,以便于其他请求复用。服务器同样会响应这个字段,一个可以复用的TCP连接就建立了,直到客户端或服务器主动关闭连接。但是,这不是标准字段,不同实现的行为可能不一致,因此不是根本的解决办法。
HTTP 1.0 请求的例子:
GET /index.html HTTP/1.0
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2)
Accept: */*
第一行是请求命令,必须在尾部添加协议版本号HTTP/1.0。第二行描述了客户端信息。第三行描述可以接受哪些数据类型。
HTTP/1.0响应的例子:
HTTP/1.0 200 OK
Content-Type: text/plain
Content-Length: 137582
Expires: Thu, 05 Dec 1997 16:00:00 GMT
Last-Modified: Wed, 5 August 1996 15:55:28 GMT
Server: Apache 0.84
<html>
<body>Hello World</body>
</html>
响应的格式是:头信息 + 一个空行(\r\n) + 数据
第一行是:协议版本 + 状态码 + 状态描述
2.1 Content-Type 字段说明
Content-Type是用来标识资源的MIME类型。
MIME类型:媒体类型(Multipurpose Internet Mail Extensions 或 MIME 类型 )是一种标准,用来表示文档、文件或字节流的性质和格式。每个MIME类型值包括一级类型和二级类型,之间用斜杠分隔
浏览器通常使用MIME类型(而不是文件扩展名)来确定如何处理URL,因此Web服务器在响应头中添加正确的MIME类型非常重要。如果配置不正确,浏览器可能会曲解文件内容,网站将无法正常工作,并且下载的文件也会被错误处理。
关于字符的编码,HTTP/1.0版规定,头信息必须是 ASCII 码,后面的数据可以是任何格式。因此,服务器回应的时候,必须告诉客户端,数据是什么格式,这就是Content-Type字段的作用。
常见的Content-Type字段的值:
text/plain 文本文件默认值。即使它意味着未知的文本文件,但浏览器认为是可以直接展示的。
text/html 所有的HTML内容都应该使用这种类型
text/css 要被解析为CSS的任何CSS文件必须指定为text/css
image/jpeg JPEG 图片
image/png PNG 图片
image/svg+xml SVG图片 (矢量图)
audio/mp4 MP4
video/mp4
application/javascript
application/pdf
application/zip
application/atom+xml
除了预定义的类型,厂商也可以自定义类型:application/vnd.debian.binary-package,
MIME类型还可以在尾部使用分号,添加参数:Content-Type: text/html; charset=utf-8,这句话的意思是发送的是网页,而且编码是UTF-8。
客户端请求的时候,可以使用Accept字段声明自己可以接受哪些数据格式:Accept: */*,这句话的意思是客户端声明自己可以接受任何格式的数据。
MIME类型还可以在其他的地方使用,如HTML中:
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8" />
<!-- 等同于 -->
<meta charset="utf-8" />
3. HTTP/1.1
1997年1月,HTTP 1.1 版本发布,只比 1.0版本晚了半年,1.1 版本进一步完善了 HTTP 协议,直到现在还是最主流的版本。
HTTP 1.1 增加了如下改进:
新增了请求方法:
PUT、PATCH、HEAD、OPTIONS、DELETE请求头信息中增加了Host字段:能够使不同域名配置在同一个IP地址的服务器上
新增两个缓存字段,解决1.0版本缓存缺陷,Cache-Control强缓存,Etag & If-None-Match协商缓存
管道机制(pipelining):客户端可以同时发送多个请求,以降低通信延迟
假如客户端需要发送两个请求。在 1.1 版本以前,在同一个TCP连接里,先发送A请求,服务器响应后,在发送B请求。管道机制则允许浏览器同时发送A请求和B请求,但是服务器还是按照顺序,先响应A请求,完成后在响应B请求。
引入了持久连接(persistent connection):节省了多次打开TCP连接加载网页文档资源的时间
即TCP连接默认不关闭,可以被多个请求复用,不用声明
Connection: keep-alive。客户端和服务器发现对方一段时间没有活动,就可以主动关闭连接。不过规范的做法是客户端在最后一个请求时,发送Connection: close,明确要求服务器关闭TCP连接。目前,对于同一个域名,大多数浏览器允许同时建立6个持久连接。
一个TCP连接现在可以传送多个回应,势必就要有一种机制,区分数据包是属于哪一个回应的。这就是
Content-length字段的作用,声明本次回应的数据长度。Content-Length: 3495:本次回应的长度是3495个字节,后面的字节就属于下一个回应了。在1.0版中,
Content-Length字段不是必需的,因为浏览器发现服务器关闭了TCP连接,就表明收到的数据包已经全了。响应分块传输编码:利于传输大文件
使用Content-Length字段的前提条件是服务器在响应前,必须要知道数据的长度。
对于一些耗时的动态操作来说,服务器要等待所有操作完成后,才能发送数据,显然这样的效率不高。更好的处理方法是,产生一块数据就发送一块,采用"流模式"(stream)取代"缓存模式"(buffer)。
因此, 1.1 版本规定可以不使用Content-Length字段,而使用"分块传输编码"(chunked transfer encoding)。只要请求或回应的头信息有
Transfer-Encoding字段,就表明回应将由数量未定的数据块组成。每个非空的数据块之前,会有一个16进制的数值,表示这个块的长度。最后是一个大小为0的块,就表示本次回应的数据发送完了。下面是一个例子。HTTP/1.1 200 OK Content-Type: text/plain Transfer-Encoding: chunked 25 This is the data in the first chunk 1C and this is the second one 3 con 8 sequence 0
3.1 HTTP 1.1 缺点
虽然1.1版允许复用TCP连接,但是同一个TCP连接里面,所有的数据通信是按次序进行的。服务器只有处理完一个回应,才会进行下一个回应。要是前面的回应特别慢,后面就会有许多请求排队等着。这称为"队头堵塞"(Head-of-line blocking)。
为了避免这个问题,只有两种方法:一是减少请求数,二是同时多开持久连接。这导致了很多的网页优化技巧,比如合并脚本和样式表、将图片嵌入CSS代码、域名分片(domain sharding)等等。如果HTTP协议设计得更好一些,这些额外的工作是可以避免的。
4. SPDY协议
2009年,谷歌公开了自行研发的 SPDY 协议,主要解决 HTTP/1.1 效率不高的问题。
这个协议在Chrome浏览器上证明可行以后,就被当作 HTTP/2 的基础,主要特性都在 HTTP/2 之中得到继承。
5. HTTP/2
2015年,HTTP/2 发布。它不叫 HTTP/2.0,是因为标准委员会不打算再发布子版本了,下一个新版本将是 HTTP/3。
5.1 二进制协议
HTTP/1.1 版的头信息肯定是文本(ASCII编码),数据体可以是文本,也可以是二进制。HTTP/2 则是一个彻底的二进制协议,头信息和数据体都是二进制,并且统称为"帧"(frame):头信息帧和数据帧。
二进制协议的一个好处是,可以定义额外的帧。HTTP/2 定义了近十种帧,为将来的高级应用打好了基础。如果使用文本实现这种功能,解析数据将会变得非常麻烦,二进制解析则方便得多。
5.2 多工
HTTP/2 复用TCP连接,在一个连接里,客户端和浏览器都可以同时发送多个请求或回应,而且不用按照顺序一一对应,这样就避免了"队头堵塞"。
举例来说,在一个TCP连接里面,服务器同时收到了A请求和B请求,于是先回应A请求,结果发现处理过程非常耗时,于是就发送A请求已经处理好的部分, 接着回应B请求,完成后,再发送A请求剩下的部分。
这样双向的、实时的通信,就叫做多工(Multiplexing)。
5.3 数据流
因为 HTTP/2 的数据包不是按顺序发送的,同一个连接里面连续的数据包,可能属于不同的响应。因此,必须要对数据包做标记,指出它属于哪个回应。
HTTP/2 将每个请求或响应的所有数据包,称为一个数据流(stream)。每个数据流都有一个独一无二的编号。数据包发送的时候,都必须标记数据流ID,用来区分它属于哪个数据流。另外还规定,客户端发出的数据流ID一律为奇数,服务器发出的ID为偶数。
数据流发送到一半的时候,客户端和服务器都可以发信号(RST_STREAM帧),取消这个数据流。1.1版本取消数据流的唯一方法,就是关闭TCP连接。HTTP/2 可以取消某一次的请求,同时保证TCP连接还打开着,可以被其他请求使用。
客户端还可以指定数据流的优先级。优先级越高,服务器就会越早响应。
5.4 头信息压缩
HTTP 每次请求都必须附上所有信息。所以请求的很多字段都是重复的,比如Cookie和User Agent,一样的内容,每次请求都必须附带,这回浪费很多宽带,也影响速度。
HTTP/2 引入了头信息压缩机制(header compression)。一方面,头信息使用gzip或compress压缩后再发送;另一方面,客户端和服务器同时维护一张头信息表,所有字段都会存入这个表,生成一个索引号,以后就不发送同样字段了,只发送索引号,这样就提高速度了。
5.5 服务器推送
HTTP/2 允许服务器未经请求,主动向客户端发送资源,这叫做服务器推送(server push)。
常见场景是客户端请求一个网页,这个网页里面包含很多静态资源。正常情况下,客户端必须收到网页后,解析HTML源码,发现有静态资源,再发出静态资源请求。其实,服务器可以预期到客户端请求网页后,很可能会再请求静态资源,所以就主动把这些静态资源随着网页一起发给客户端了。
6. HTTPS
由于HTTP是不加密通信,所有信息明文传输,因此带来了如下风险:
窃听风险(eavesdropping):通信使用明文传输,第三方可以获知通信内容
篡改风险(tampering):无法证明报文的完整性,第三方可以修改通信内容
冒充风险(pretending):不验证通信方的身份,第三方可以冒充他人身份参与通信
为了解决HTTP安全性问题,产生了HTTPS,HTTPS解决了上面提到的问题:
窃听风险(eavesdropping):所有信息都是加密传播,第三方无法窃听
篡改风险(tampering):具有校验机制,一旦被篡改,通信双方会立刻发现
冒充风险(pretending):配备身份证书,防止身份被冒充
HTTPS(Hypertext Transfer Protocol over Secure Socket Layer),是以安全为目标的HTTP通道,是HTTP的安全版。即HTTP下加入SSL层,HTTPS的安全基础是SSL,因此加密的详细内容就需要SSL。
SSL/TLS协议的基本思路是采用公钥加密法,也就是说,客户端先向服务器端索要公钥,然后用公钥加密信息,服务器收到密文后,用自己的私钥解密
如果想要建立HTTPS连接,则首先必须从受信任的证书颁发机构(CA)Gworg机构注册 SSL证书。安装SSL证书后,网站地址栏HTTP后面就会多一个“S”,还有绿色安全锁标志。
HTTPS = HTTP + TLS/SSL

6.1 非对称加密
非对称加密会有一对秘钥:公钥和私钥。 公钥加密的内容,只有私钥可以解开,私钥加密的内容,所有的公钥都可以解开(当然是指和秘钥是一对的公钥)。
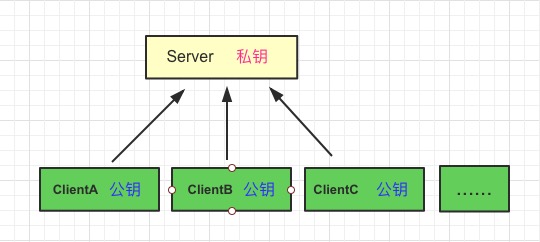
私钥只保存在服务器端,公钥可以发送给所有的客户端。
在传输公钥的过程中,肯定也会有被中间人获取的风险,但在目前的情况下,至少可以保证客户端通过公钥加密的内容,中间人是无法破解的,因为私钥只保存在服务器端,只有私钥可以破解公钥加密的内容。
现在还存在一个问题,如果公钥被中间人拿到篡改呢:
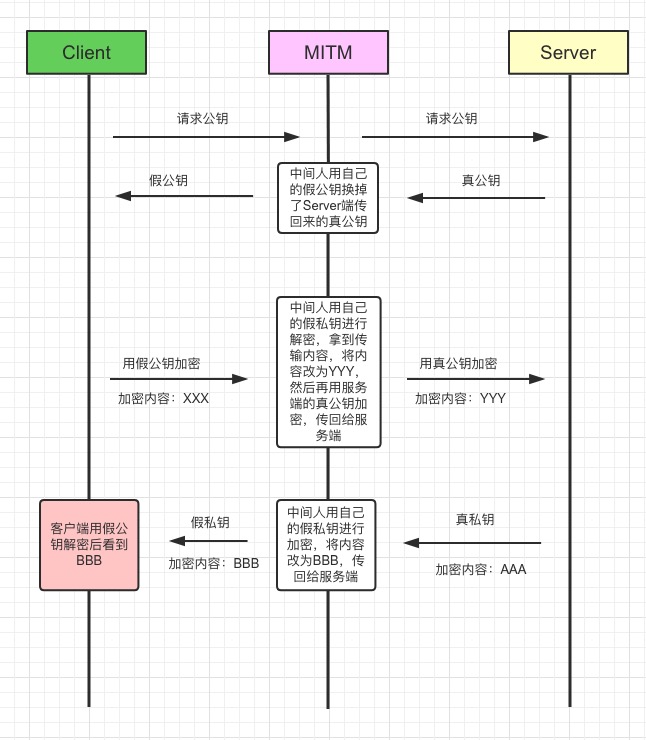
客户端拿到的公钥是假的,如何解决这个问题?
6.2 第三方认证
公钥被掉包,是因为客户端无法分辨传回公钥的到底是中间人,还是服务器,这也是密码学中的身份验证问题。
在HTTPS中,使用 证书 + 数字签名 来解决这个问题。
这里假设加密方式是MD5,将网站的信息加密后通过第三方机构的私钥再次进行加密,生成数字签名。
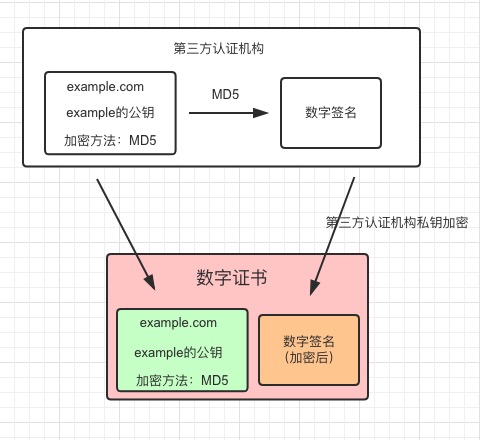
数字证书 = 网站信息 + 数字签名
假如中间人拦截后把服务器的公钥替换为自己的公钥,因为数字签名的存在,会导致客户端验证签名不匹配,这样就防止了中间人替换公钥的问题。
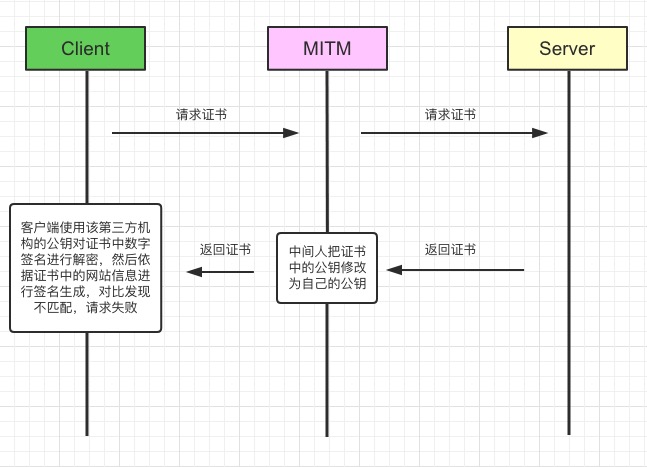
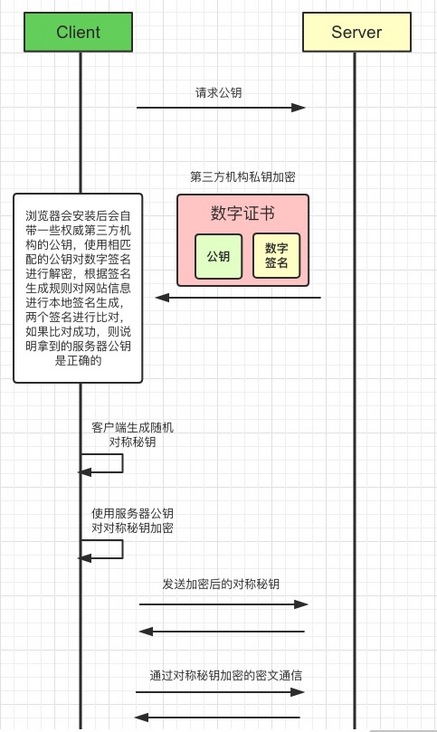
浏览器安装后会内置一些权威第三方认证机构的公钥,比如VeriSign、Symantec以及GlobalSign等等,验证签名的时候直接就从本地拿到相应第三方机构的公钥,对私钥加密后的数字签名进行解密得到真正的签名,然后客户端利用签名生成规则进行签名生成,看两个签名是否匹配,如果匹配认证通过,不匹配则获取证书失败。
6.3 为什么要有签名?
第三方认证机构是一个开放的平台,我们可以去申请,中间人也可以去申请:
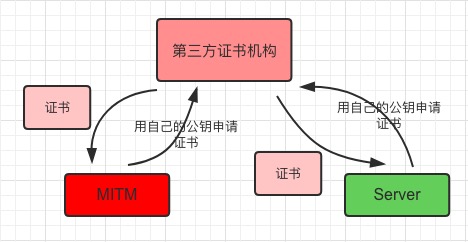
如果没有签名,只对网站信息进行第三方机构私钥加密的话,会存在下面的问题:
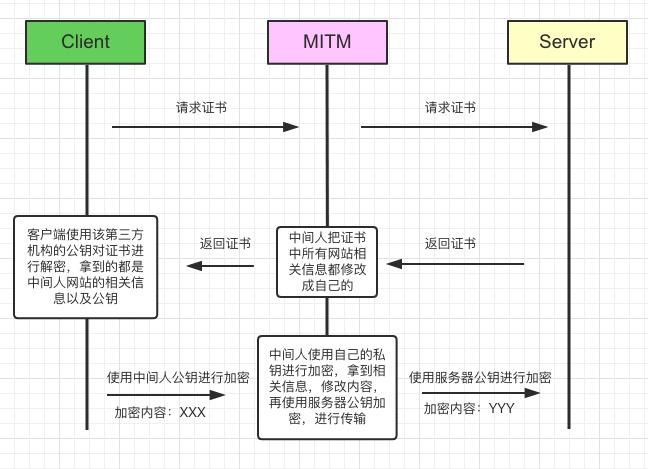
因为没有认证,所以中间人也向第三方认证机构进行申请,然后拦截后把所有的信息都替换成自己的,客户端仍然可以解密,并且无法判断这是服务器的还是中间人的,最后造成数据泄露。
6.4 对称加密
在安全的拿到服务器的公钥之后,客户端会随机生成一个对称秘钥,使用服务器公钥加密,传输给服务端,此后,相关的 Application Data 就通过这个随机生成的对称秘钥进行加密/解密,服务器也通过该对称秘钥进行解密/加密:
7. URI、URL、URN
- URI:Uniform Resource Identifier,统一资源标识符
- URL:Uniform Resource Locator,统一资源定位器
- URN:Uniform Resource Name,统一资源名称
URI、URL、URN三者关系:
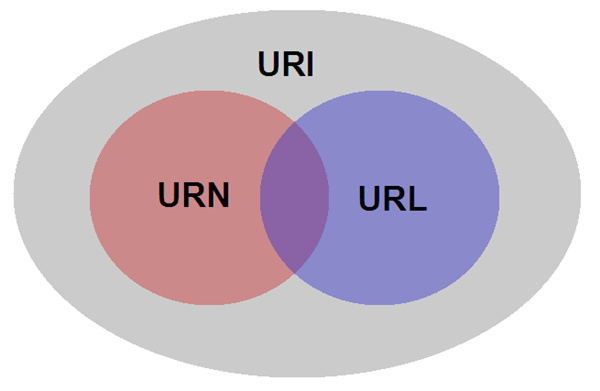
URI统一资源标识符,用来标记一个资源的唯一标识。URI是抽象的定义,不管用什么方法标识,只要能定位一个资源,就叫URI。
URI主要由两个子集构成:
- URL:通过描述资源的位置来描述资源
- URN:通过名字来识别资源,和位置无关。使用URN可以在不知道网络位置和访问方式情况下访问资源
举个例子:通过身份证(URI)找人,可以使用身份证上的地址(URL)找,也可以通过身份证号+姓名(URN) 找。
7.1 URL格式
一个URL例子:
http://www.example.com/f2e/js/ajax.html
我们常见的URL有三部分组成:
- 协议:http、https
- 服务器位置:域名或IP地址
- 资源路径
通用的URL由如下几部分组成:

- 协议:指定使用的传输一些,如:http、https、ftp等
- 登陆信息:可选,指定用户名、密码登陆验证,现在不常见了,都是通过页面登陆方式
| 名字 | 说明 |
|---|---|
| 协议 | 指定使用的传输协议,如:http、https、ftp等 |
| 登陆信息 | 可选,指定用户名、密码登陆验证,现在不常见了,都是通过页面登陆方式 |
| 服务器地址 | 可以是域名:www.example.com,也可以是IP: 192.186.3.5 |
| 服务器端口 | 可选,指定服务器的网络端口,省略则使用默认端口,http:80,https:443 |
| 文件路径 | 资源的路径,也就是存放位置,不一定和物理路径完全对应,符合web服务器路由约定即可 |
| 参数 | 资源需要的参数,?a=1&b=2&=3,get方法常用这种形式传参 |
| 片段 | 用于指定网络资源中的片断。html页面中片段则是描点。很多MVVM框架用作了路由功能 |