[TOC]
CSRF攻击
1. 什么是CSRF
CSRF(Cross-site request forgery)跨站请求伪造:攻击者诱导受害者进入第三方网站,在第三方网站中,向被攻击网站发送跨站请求。利用受害者在被攻击网站已经获取的注册凭证,绕过后台的用户验证,达到冒充用户对被攻击的网站执行某项操作的目的。
一个典型的CSRF攻击有着如下的流程:
- 受害者登录a.com,并保留了登录凭证(Cookie)。
- 攻击者引诱受害者访问了b.com。
- b.com 向 a.com 发送了一个请求:a.com/act=xx。浏览器会默认携带a.com的Cookie。
- a.com接收到请求后,对请求进行验证,并确认是受害者的凭证,误以为是受害者自己发送的请求。
- a.com以受害者的名义执行了act=xx。
- 攻击完成,攻击者在受害者不知情的情况下,冒充受害者,让a.com执行了自己定义的操作。
CSRF的特点:
- 攻击一般发起在第三方网站,而不是被攻击的网站。被攻击的网站无法防止攻击发生。
- 攻击利用受害者在被攻击网站的登录凭证,冒充受害者提交操作;而不是直接窃取数据。
- 整个过程攻击者并不能获取到受害者的登录凭证,仅仅是“冒用”。
- 跨站请求可以用各种方式:图片URL、超链接、CORS、Form提交等等。部分请求方式可以直接嵌入在第三方论坛、文章中,难以进行追踪。
CSRF通常是跨域的,因为外域通常更容易被攻击者掌控。但是如果本域下有容易被利用的功能,比如可以发图和链接的论坛和评论区,攻击可以直接在本域下进行,而且这种攻击更加危险。
1.1 几种常见的攻击类型
1.1.1 GET类型的CSRF
GET类型的CSRF利用非常简单,只需要一个HTTP请求,一般会这样利用:
<img src="http://bank.example/withdraw?amount=10000&for=hacker" >
在受害者访问含有这个img的页面后,浏览器会自动向http://bank.example/withdraw?account=xiaoming&amount=10000&for=hacker发出一次HTTP请求。bank.example就会收到包含受害者登录信息的一次跨域请求。
1.1.2 POST类型的CSRF
这种类型的CSRF利用起来通常使用的是一个自动提交的表单,如:
<form action="http://bank.example/withdraw" method=POST>
<input type="hidden" name="account" value="xiaoming" />
<input type="hidden" name="amount" value="10000" />
<input type="hidden" name="for" value="hacker" />
</form>
<script> document.forms[0].submit(); </script>
访问该页面后,表单会自动提交,相当于模拟用户完成了一次POST操作。
POST类型的攻击通常比GET要求更加严格一点,但仍并不复杂。任何个人网站、博客,被黑客上传页面的网站都有可能是发起攻击的来源,后端接口不能将安全寄托在仅允许POST上面。
1.1.3 链接类型的CSRF
链接类型的CSRF并不常见,比起其他两种用户打开页面就中招的情况,这种需要用户点击链接才会触发。这种类型通常是在论坛中发布的图片中嵌入恶意链接,或者以广告的形式诱导用户中招,攻击者通常会以比较夸张的词语诱骗用户点击,例如:
<a href="http://test.com/csrf/withdraw.php?amount=1000&for=hacker" taget="_blank">
重磅消息!!
<a/>
由于之前用户登录了信任的网站A,并且保存登录状态,只要用户主动访问上面的这个PHP页面,则表示攻击成功。
2. CSRF防护策略
CSRF的两个特点:
- CSRF(通常)发生在第三方域名。
- CSRF攻击者不能获取到Cookie等信息,只是使用。
针对这两点,我们可以专门制定防护策略,如下:
- 阻止不明外域的访问
- 同源检测
- Samesite Cookie
- 提交时要求附加本域才能获取的信息
- CSRF Token
- 双重Cookie验证
2.1 阻止不明外域的访问
2.1.1 同源检测
既然CSRF大多来自第三方网站,那么我们就直接禁止外域(或者不受信任的域名)对我们发起请求。
那么问题来了,我们如何判断请求是否来自外域呢?
在HTTP协议中,每一个异步请求都会携带两个Header,用于标记来源域名:
- Origin Header
- Referer Header
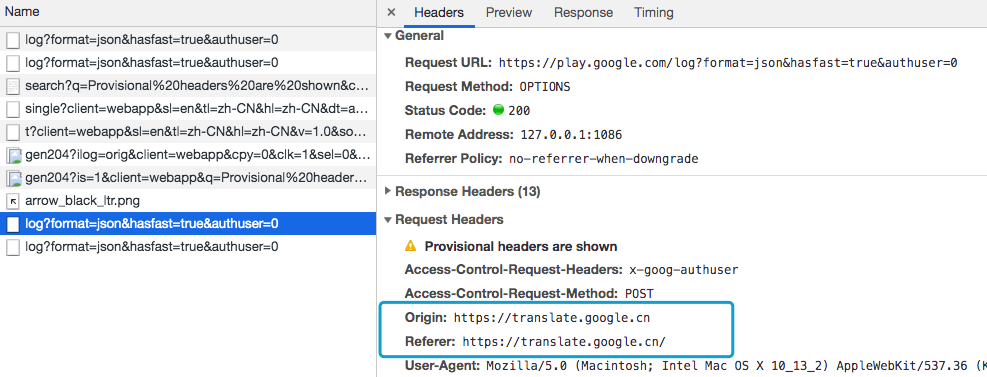
截图的是Google翻译网站:https://translate.google.cn/
这两个Header在浏览器发起请求时,大多数情况会自动带上,并且不能由前端自定义内容。 服务器可以通过解析这两个Header中的域名,确定请求的来源域。
2.1.1.1 使用Origin Header确定来源域名
在部分与CSRF有关的请求中,请求的Header中会携带Origin字段。字段内包含请求的域名(不包含path及query)。 如果Origin存在,那么直接使用Origin中的字段确认来源域名就可以。 但是Origin在以下两种情况下并不存在:
- IE11同源策略: IE 11 不会在跨站CORS请求上添加Origin标头,Referer头将仍然是唯一的标识。最根本原因是因为IE 11对同源的定义和其他浏览器有不同,有两个主要的区别,可以参考MDN Same-origin_policy#IE_Exceptions
- 302重定向: 在302重定向之后Origin不包含在重定向的请求中,因为Origin可能会被认为是其他来源的敏感信息。对于302重定向的情况来说都是定向到新的服务器上的URL,因此浏览器不想将Origin泄漏到新的服务器上。
2.1.1.2 使用Referer Header确定来源域名
根据HTTP协议,在HTTP头中有一个字段叫Referer,记录了该HTTP请求的来源地址。 对于Ajax请求,图片和script等资源请求,Referer为发起请求的页面地址。对于页面跳转,Referer为打开页面历史记录的前一个页面地址。因此我们使用Referer中链接的Origin部分可以得知请求的来源域名。
这种方法并非万无一失,Referer的值是由浏览器提供的,虽然HTTP协议上有明确的要求,但是每个浏览器对于Referer的具体实现可能有差别,并不能保证浏览器自身没有安全漏洞。使用验证 Referer 值的方法,就是把安全性都依赖于第三方(即浏览器)来保障,从理论上来讲,这样并不是很安全。在部分情况下,攻击者可以隐藏,甚至修改自己请求的Referer。
2014年,W3C的Web应用安全工作组发布了Referrer Policy草案,对浏览器该如何发送Referer做了详细的规定。截止现在新版浏览器大部分已经支持了这份草案,我们终于可以灵活地控制自己网站的Referer策略了。新版的Referrer Policy规定了五种Referer策略:No Referrer、No Referrer When Downgrade、Origin Only、Origin When Cross-origin、和 Unsafe URL。之前就存在的三种策略:never、default和always,在新标准里换了个名称。他们的对应关系如下:
| 策略名称 | 属性值(新) | 属性值(旧) |
|---|---|---|
| No Referrer | no-Referrer | never |
| No Referrer When Downgrade | no-Referrer-when-downgrade | default |
| Origin Only | (same or strict) origin | origin |
| Origin When Cross Origin | (strict) origin-when-crossorigin | - |
| Unsafe URL | unsafe-url | always |
根据上面的表格因此需要把Referrer Policy的策略设置成same-origin,对于同源的链接和引用,会发送Referer,referer值为Host不带Path;跨域访问则不携带Referer。例如:aaa.com引用bbb.com的资源,不会发送Referer。
设置Referrer Policy的方法有三种:
- 在CSP设置
- 页面头部增加meta标签
- a标签增加referrerpolicy属性
上面说的这些比较多,但我们可以知道一个问题:攻击者可以在自己的请求中隐藏Referer。如果攻击者将自己的请求这样填写:
<img src="http://bank.example/withdraw?amount=10000&for=hacker" referrerpolicy="no-referrer">
那么这个请求发起的攻击将不携带Referer。
另外在以下情况下Referer没有或者不可信:
1、IE6、7下使用window.location.href=url进行界面的跳转,会丢失Referer。
2、IE6、7下使用window.open,也会缺失Referer。
3、HTTPS页面跳转到HTTP页面,所有浏览器Referer都丢失。
4、点击Flash上到达另外一个网站的时候,Referer的情况就比较杂乱,不太可信。
2.1.2 无法确认来源域名情况
当Origin和Referer头文件不存在时该怎么办?如果Origin和Referer都不存在,建议直接进行阻止,特别是如果您没有使用随机CSRF Token(参考下方)作为第二次检查。
2.1.3 如何阻止外域请求
通过Header的验证,我们可以知道发起请求的来源域名,这些来源域名可能是网站本域,或者子域名,或者有授权的第三方域名,又或者来自不可信的未知域名。
当来请求来源不可信的域名时,我们可以阻止这些请求。
但是有的请求是页面请求(比如网站的主页),而来源是搜索引擎的链接(例如百度的搜索结果),也会被当成疑似CSRF攻击。所以在判断的时候需要过滤掉页面请求情况,通常Header符合以下情况:
Accept: text/html
Method: GET
但相应的,页面请求就暴露在了CSRF的攻击范围之中。如果你的网站中,在页面的GET请求中对当前用户做了什么操作的话,防范就失效了。
例如,下面的页面请求:
GET https://example.com/addComment?comment=XXX&dest=orderId
注:这种严格来说并不一定存在CSRF攻击的风险,但仍然有很多网站经常把主文档GET请求挂上参数来实现产品功能,但是这样做对于自身来说是存在安全风险的。
另外,前面说过,CSRF大多数情况下来自第三方域名,但并不能排除本域发起。如果攻击者有权限在本域发布评论(含链接、图片等,统称UGC),那么它可以直接在本域发起攻击,这种情况下同源策略无法达到防护的作用。
综上所述:同源验证是一个相对简单的防范方法,能够防范绝大多数的CSRF攻击。但这并不是万无一失的,对于安全性要求较高,或者有较多用户输入内容的网站,我们就要对关键的接口做额外的防护措施。
2.2 请求提交时要求附加本域才能获取的信息
2.2.1 CSRF Token
前面讲到CSRF的另一个特征是,攻击者无法直接窃取到用户的信息(Cookie,Header,网站内容等),仅仅是冒用Cookie中的信息。
而CSRF攻击之所以能够成功,是因为服务器误把攻击者发送的请求当成了用户自己的请求。那么我们可以要求所有的用户请求都携带一个CSRF攻击者无法获取到的Token。服务器通过校验请求是否携带正确的Token,来把正常的请求和攻击的请求区分开,也可以防范CSRF的攻击。
CSRF Token的防护策略分为三个步骤:
1、将CSRF Token输出到页面中
用户打开页面的时候,服务器会生成一个token,该token不能放在cookie中,否则又会被攻击者冒用,为了安全,token最好还是放在session中,之后再每次加载页面时,先用API请求到token,然后使用JS遍历整个DOM树,对于DOM中所有的a和form标签后加入token,这样可以解决大部分请求,但对于页面加载后动态生成的HTML代码,这种方法没用,还需要程序员在编码是手动添加token。
2、页面提交的请求携带这个Token
对于GET请求,Token将附在请求地址之后,这样URL 就变成 http://url?csrftoken=tokenvalue。 而对于 POST 请求来说,要在 form 的最后加上:
<input type=”hidden” name=”csrftoken” value=”tokenvalue”/>
这样,就把Token以参数的形式加入请求了。
3、服务器验证Token是否正确
当用户从客户端得到了Token,再次提交给服务器的时候,服务器需要判断Token的有效性,验证过程是先解密Token,对比加密字符串以及时间戳,如果加密字符串一致且时间未过期,那么这个Token就是有效的。
这种方法要比之前检查Referer或者Origin要安全一些,Token可以在产生并放于Session之中,然后在每次请求时把Token从Session中拿出,与请求中的Token进行比对,但这种方法的比较麻烦的在于如何把Token以参数的形式加入请求。
这个Token的值必须是随机生成的,这样它就不会被攻击者猜到,考虑利用Java应用程序的java.security.SecureRandom类来生成足够长的随机标记,替代生成算法包括使用256位BASE64编码哈希,选择这种生成算法的开发人员必须确保在散列数据中使用随机性和唯一性来生成随机标识。通常,开发人员只需为当前会话生成一次Token。在初始生成此Token之后,该值将存储在会话中,并用于每个后续请求,直到会话过期。当最终用户发出请求时,服务器端必须验证请求中Token的存在性和有效性,与会话中找到的Token相比较。如果在请求中找不到Token,或者提供的值与会话中的值不匹配,则应中止请求,应重置Token并将事件记录为正在进行的潜在CSRF攻击。
4、分部署Token校验
在大型网站中,使用Session存储CSRF Token会带来很大的压力。访问单台服务器session是同一个。但是现在的大型网站中,我们的服务器通常不止一台,可能是几十台甚至几百台之多,甚至多个机房都可能在不同的省份,用户发起的HTTP请求通常要经过像Ngnix之类的负载均衡器之后,再路由到具体的服务器上,由于Session默认存储在单机服务器内存中,因此在分布式环境下同一个用户发送的多次HTTP请求可能会先后落到不同的服务器上,导致后面发起的HTTP请求无法拿到之前的HTTP请求存储在服务器中的Session数据,从而使得Session机制在分布式环境下失效,因此在分布式集群中CSRF Token需要存储在Redis之类的公共存储空间。
由于使用Session存储,读取和验证CSRF Token会引起比较大的复杂度和性能问题,目前很多网站采用Encrypted Token Pattern方式。这种方法的Token是一个计算出来的结果,而非随机生成的字符串。这样在校验时无需再去读取存储的Token,只用再次计算一次即可。
这种Token的值通常是使用UserID、时间戳和随机数,通过加密的方法生成。这样既可以保证分布式服务的Token一致,又能保证Token不容易被破解。
在token解密成功之后,服务器可以访问解析值,Token中包含的UserID和时间戳将会被拿来被验证有效性,将UserID与当前登录的UserID进行比较,并将时间戳与当前时间进行比较。
5、token验证总结
Token是一个比较有效的CSRF防护方法,只要页面没有XSS漏洞泄露Token,那么接口的CSRF攻击就无法成功。
但是此方法的实现比较复杂,需要给每一个页面都写入Token(前端无法使用纯静态页面),每一个Form及Ajax请求都携带这个Token,后端对每一个接口都进行校验,并保证页面Token及请求Token一致。这就使得这个防护策略不能在通用的拦截上统一拦截处理,而需要每一个页面和接口都添加对应的输出和校验。这种方法工作量巨大,且有可能遗漏。
验证码和密码其实也可以起到CSRF Token的作用哦,而且更安全。为什么很多银行等网站会要求已经登录的用户在转账时再次输入密码,现在是不是有一定道理了?
2.2.2 双重cookie验证
在会话中存储CSRF Token比较繁琐,而且不能在通用的拦截上统一处理所有的接口。
另一种防御措施是使用双重提交cookie。利用CSRF攻击不能获取到用户cookie的特点,我们可以要求ajax和表单请求携带一个cookie中的值。
双重cookie采用一下流程:
- 在用户访问网站页面时,向请求域名注入一个cookie,内容为随机字符串
- 在前端向后端发起请求时,取出cookie,并添加到URL的参数中
- 后端接口验证cookie中的字段与URL参数中的字段是否一致,不一致则拒绝
参考资料
https://segmentfault.com/a/1190000016659945
https://segmentfault.com/a/1190000018073845